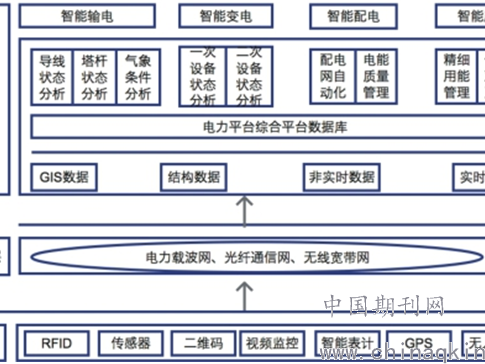
哎呦喂,你瞧瞧现在这世道,AI工具多得跟雨后春笋似的,今儿个冒出个“百炼”,明儿个又来个“Dify”,后儿没准儿又蹦出个啥新玩意-1。可甭管是公司里想整点自动化流程,还是自个儿捣鼓点智能应用,最头疼的就是——咋让这些不同来路、不同脾性的AI模型,都能在咱的地盘上乖乖听话、顺畅跑起来? 这就不得不唠唠那个让不少技术老鸟都挠头的核心功夫:AI兼容设置。
这玩意儿啊,说玄乎也玄乎,说简单也简单。它可不是简单填个API密钥就完事儿了,里头门道深着呢。搞得好,各类AI模型在你手里就像交响乐团,和谐奏鸣;搞不好,那就是一场灾难,报错提示能看得你眼花缭乱,不是“内存不足”就是“连接失败”,好好的项目直接卡壳-4。所以啊,咱们今天就来掰扯掰扯,怎么把这AI兼容设置的活儿,干得漂亮,干得省心。

一、为啥非得折腾“兼容”这事儿?场景是王啊!
咱首先得整明白,为啥不能“从一而终”,非得让系统能兼容多个AI?答案就俩字:场景。不同的活儿,需要不同的“专家”来干-3。

举个栗子,你公司客服系统处理日常问答,可能用个7B参数的小模型就够快够省钱了;但要是让AI帮你分析一份几十页的法律合同,找出潜在风险点,那就得上那种支持长上下文、推理能力杠杠的“大块头”模型,比如什么32B参数的-4。再比如,你做个创意写作工具,需要天马行空,那得调高“温度”(Temperature)参数,让输出更有随机性;要是生成严谨的代码或者财务报告,就得把“温度”调低,让它更确定性、更靠谱-5。
所以说,一个灵活的系统,必须能根据不同的任务场景,快速、平滑地切换背后的AI引擎。这就好比你的手机,能根据是拍人像还是拍夜景,自动调用不同的摄像头和算法。AI兼容设置,就是为你构建这套“自动调用”机制的地基。它决定了你的应用是“全能战士”还是“偏科生”-3。
二、兼容设置的核心“三板斧”
那具体要折腾些啥呢?别看各家平台长得不一样,核心都绕不开下面这几样。搞懂了这些,你心里就有张地图了。
第一板斧:接口与通道的标准化
这是最基础的一层。现在比较主流的方式,是让系统通过一个统一的、类OpenAI的API接口格式去跟各种模型对话-1。就像给所有模型一个统一的“插座”标准。比如,不管背后是阿里云的百炼、还是百度文心,或者是本地部署的Ollama模型,前端都尝试用类似 https://api.endpoint/v1/chat/completions 这样的地址和JSON格式去发送请求和接收回复-1-5。
很多开源工具和套件(比如前面提到的ai-client-kit)就是干这个的,它们帮你封装了不同模型的差异,让你用一套代码就能接入多种AI-2。但这里有个坑:不是所有模型提供商都百分之百兼容这个标准,返回的数据格式可能有些“方言差异”-1。这时候就需要在回调函数里做点“数据转换”的小手术,把不同模型的回复,修剪成你系统能理解的统一格式-1。
第二板斧:模型与参数的动态配置
光能连接上还不够,还得能灵活配置。这就需要一个清晰的后台,让你能方便地管理不同模型的“档案”。每份“档案”里至少得包含这几样东西:
模型标识:叫啥名,是
gpt-4还是qwen-long-1。接入点:API的URL地址是哪儿-6。
钥匙:对应的API Key-6。
个性参数:比如刚才说的“温度”(控制创造性)、最大生成长度等-5。有些高级模型可能还支持是否开启“联网”、“深度思考”等开关,这些也得能配置-1。
最好还能有个“模型兜底”策略。比如主用的模型万一抽风了,能自动切换到备用模型,保证服务不中断。
第三板斧:上下文与提示词的适配管理
这是最容易忽略,但也极其影响效果的一层。不同的AI模型,对“怎么跟它说话”有不同的偏好。这就涉及到“对话模板”和“系统提示词”-8。
比如,有的模型喜欢在对话前加特定的符号,如 <|im_start|>system,有的则用更简单的 ### Instruction: 格式-8。如果你用错了模板,模型可能就“看不懂”或者“瞎回答”。在AI兼容设置中,为每个支持的模型预置或允许自定义正确的对话模板,至关重要。
系统提示词也是同理。你可以通过它来设定AI的角色(“你是一个编程专家”)、回答的语种(“请用中文回答”-8)、以及需要遵守的规则。一个好的兼容设置,应该允许你为不同的场景和模型,定制不同的提示词,并把它们和模型配置关联起来。
三、参数微调:让AI说出你想要的“方言”
配置好了通道和模型,就像给车加满了油、选好了路。但想开得又稳又快,还得会调座椅、后视镜和方向盘。这就是参数微调。
“温度”是个宝,高低要搞好:这参数控制AI的“脑洞”大小。设置为0.2左右,它回答会非常严谨、确定,适合代码、数学题;调到0.8到1.2,它会更活泼、有创意,适合聊天、写文案;要是敢调到1.5以上,那它就可能开始胡说八道,只适合需要极端发散思维的场景了-5。你得根据场景灵活调整。
“重复”与“惩罚”:如果AI老是一个词儿来回说,或者车轱辘话没完,可以在高级设置里找找“频率惩罚”或“存在惩罚”这类参数,适当调高,能有效减少重复-8。
上下文长度不是越长越好:虽然现在很多模型都宣传支持超长上下文,但实际使用时,要根据你的对话真实需要来设置保留的历史轮数。设得太长,不仅浪费计算资源(可能更贵),有时反而会让AI迷失在过时的信息里-5。
四、实战避坑:那些“血与泪”的教训
理论说再多,不如踩个坑记得牢。下面这些可是很多前辈真金白银换来的经验:
硬件资源是硬门槛:在本地部署切换大模型时,最常见的报错就是“CUDA out of memory”(显存不足)或内存爆满-4。从7B模型切换到32B模型,对资源的消耗可不是线性增长,是指数级飙升!切换前务必用
nvidia-smi或系统监控工具看看你的“家底”够不够-4。配置文件,一字千金:一个冒号写错、一个路径不对,都能让一切瘫痪。比如把
http://localhost:11434写成http//localhost:11434,少个冒号,连接就直接失败-4。修改任何配置文件后,养成用命令校验一下的好习惯。版本兼容,暗藏杀机:你下载的最新版酷炫模型,可能需要特定版本的框架(比如Ollama 0.3.2+)才能跑。用旧框架去加载新格式的模型文件,分分钟报错-4。保持框架和依赖库的更新,同时也要注意测试环境的稳定性。
网络与权限,隐形杀手:尤其是本地模型服务(如Ollama),要确保客户端能访问到服务端的IP和端口。防火墙、安全组设置不对,权限没给够,都是常见问题-5。简单用
ping和telnet命令测试一下连通性,能省下很多瞎猜的时间。
五、未来已来:更智能的兼容在路上
搞定了上面这些,你已经能搭建一个相当强大的多AI兼容系统了。但技术的车轮滚滚向前,未来的AI兼容设置肯定会更“傻瓜”、更智能。
趋势已经初现端倪:比如,异构计算的普及,让你的系统可以自动调度CPU、GPU甚至专用的NPU来运行不同的AI任务,达到效率和成本的最优-3。再比如,对联邦学习等隐私计算技术的支持,能让企业在不共享原始数据的前提下,联合多个AI模型进行训练和推理,这在金融、医疗领域简直是刚需-3。
更长远看,也许未来会出现真正的“AI中间件”或“AI调度操作系统”。你只需要用自然语言描述你的需求:“帮我写个产品文案,要活泼一点,预算控制在每千次请求1块钱以内。” 系统就能自动在几十个可用的AI模型中,选择文案能力强、成本符合要求、且当前响应最快的那个,并自动配置好所有参数和提示词模板,无缝完成任务。
到那时,我们或许不再需要像今天这样,手动去抠每一个配置细节。但无论如何,今天我们对AI兼容设置底层逻辑的理解和掌握,都是通向那个智能未来的必经之路。它让你不仅是一个工具的使用者,更是智能世界的构建者。所以,别怕麻烦,沉下心来把这门“艺术”搞明白,绝对值当。