哎哟喂,现在搞系统运维的兄弟姊妹们,哪个没为监控的事情挠破过头皮?白天系统跑得好好的,一到半夜或者业务高峰,它冷不丁就给你来个“躺平”,报警信息嘀嘀嘀响个不停,等你火急火燎爬起来登录服务器一瞅——嚯,风平浪静,啥事儿没有!这种“见鬼了”的经历,真是让人憋屈又上火。说到底,这就是各种技术监控性能没做到位,东一榔头西一棒子,光看着几个CPU、内存的数字,根本摸不清系统真正的“脾气秉性”-3-6。
今天咱们就扯开嗓子唠一唠,怎么把散落在各处的监控信息给它归拢齐整了,建立起一套让你心里有底、眼里有活的性能管理体系。这可不是简单的工具堆砌,而是一门让系统“开口说话”的艺术。
先整明白:监控到底要瞅啥?可不是光看CPU“累不累”
很多人一提起监控,脑子裏蹦出来的就是任务管理器裏那个CPU使用率的曲线图,觉得它别“飙红”就万事大吉。这想法啊,就跟用体温计判断一个人是否健康一样,太片面啦!一套完整的各种技术监控性能体系,那得是给系统做全方位的“体检”,从硬件底子到软件应用,再到业务逻辑,层层都要关照到-4-7。
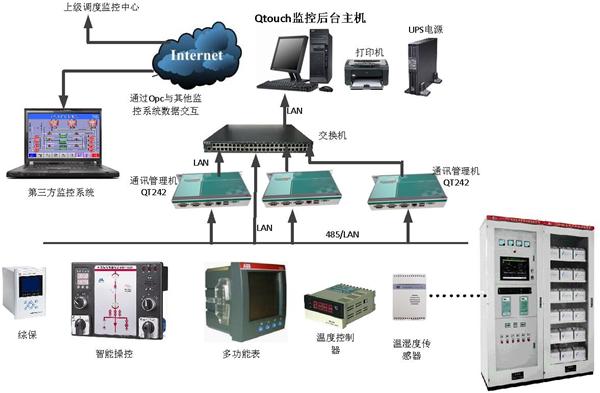
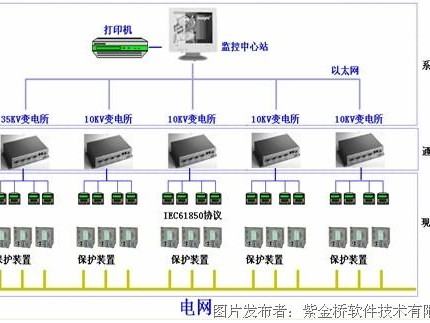
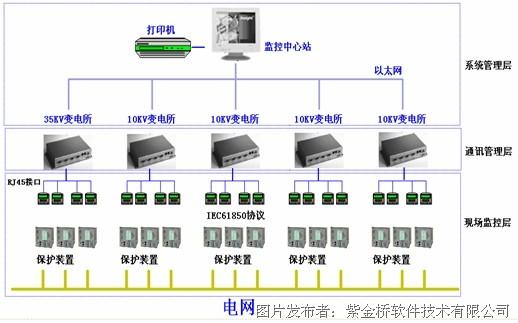
硬件层是根基:别以为上了云就不用管硬件了。服务器自身的CPU温度、风扇转速、磁盘健康状态(特别是用了RAID的,阵列卡状态很关键)、电源情况,这些底层的“身体素质”要是不行,上面盖的楼再漂亮也得晃悠。现在一般通过IPMI协议来获取这些信息-5-8。
系统层是核心:这才是我们平常关注的重点。但光看CPU使用率一个数字可不够。你得关心CPU的负载(Load Average),特别是每个核心的队列长度;关心内存不仅看用了多少,还得看Swap用了没、有没有内存泄漏的苗头;磁盘I/O更是性能杀手,读写延迟、吞吐量、IO等待时间,哪个不对劲都能让系统“卡得不行”;还有网络,进出流量、TCP连接数、丢包率,哪样都得门儿清-1-5。
应用与中间件层是关键:你的MySQL数据库连接池是不是快满了?Redis的缓存命中率掉没掉?Nginx返回的5xx错误是不是在增多?Kafka的消息有没有堆积?这些应用和中间件的指标,直接关系到业务的顺畅度-2-9。
业务层是最终目标:前面所有监控,最终都是为了业务能平稳跑起来。所以,最顶层的监控一定是业务指标:每分钟的下单量、支付成功率、用户活跃数、核心API的响应时间。业务指标一波动,你能立刻往下钻取,看到是哪个应用、哪台主机、哪个硬件环节出了岔子,这监控才算做到了家-6-9。
别再瞎报警了:建立有价值的指标体系与“黄金法则”
指标海了去了,难道全都设上报警?那你的手机怕是得永远静音了——因为报警会多到让你麻木。所以,梳理各种技术监控性能的核心,就是建立有价值的指标体系,并且聪明地设置报警。
这里给大家介绍一个非常管用的方法论——USE方法(Utilization, Saturation, Errors)。简单说,就是针对任何一种资源(比如CPU、磁盘、数据库连接),你主要关注它的三个维度-6:
使用率:比如CPU使用率70%。
饱和度:指资源排队等待的程度,比如CPU的运行队列长度。
错误数:比如网卡的错误包数量、应用日志里的错误日志。
抓住这三个核心维度去设置关键指标,比眉毛胡子一把抓要高效得多。举个例子,磁盘使用率90%不一定立刻致命,但如果磁盘I/O的等待时间(饱和度)持续很高,那系统离卡顿就不远了。
对于应用服务,业界也有个“黄金指标”的说法,主要就是四样:吞吐量(比如每秒请求数)、延迟(响应时间)、错误率(失败请求的占比)和资源使用率(应用进程本身的CPU、内存占用)-2-6。把这几个指标监控好,应用的健康状况你就掌握了八成。
报警阈值怎么设?这需要经验,更需要观察历史数据。别一拍脑袋就把CPU报警阈值设为85%,也许你的系统正常峰值就在80%。设置动态基线报警(根据历史同期数据自动计算合理范围)往往比固定阈值更科学,能减少大量“狼来了”的误报-6。
工欲善其事:选对工具,让数据自己“跑”起来
思路清楚了,就得有趁手的家伙什。监控工具的世界可谓是百花齐放,老牌劲旅和新贵翘楚各有千秋。
经典全能王:Zabbix。这家伙功能是真全乎,从网络设备、服务器到应用、数据库,几乎没有它不能监控的。支持Agent、SNMP、IPMI等多种数据采集方式,报警配置也非常灵活,适合构建企业级的一体化监控平台-5-8。
云原生时代宠儿:Prometheus + Grafana 组合。这套现在是绝对的主流,特别是对于容器化、微服务架构的环境。Prometheus负责抓取和存储时间序列数据,它的查询语言PromQL功能强大。Grafana则是数据可视化的神器,做出来的图表那叫一个漂亮直观,能把枯燥的数据变成一目了然的仪表盘-1-6。
特定领域高手:
专攻网络质量:Smokeping,它能持续测量网络延迟和丢包,生成非常直观的渐变图,专治各种网络不稳定-8。
专攻数据库:Lepus(天兔),对MySQL、Redis等数据库的监控有深度支持-9。
专攻全链路追踪:SkyWalking, Zipkin, Jaeger,用于在微服务架构中跟踪一个请求跨了无数个服务之后的完整路径和性能瓶颈,是定位复杂问题的利器-6-9。
工具选型没有最好,只有最合适。中小团队用用Prometheus+Grafana可能就很舒服了;传统IT环境深厚的大企业,用Zabbix可能整合起来更顺手。关键是,要让工具为你的监控思路服务,而不是被工具牵着鼻子走。
落地实战:从“救火”到“防火”的思维转变
监控体系建好了,可不是为了整天看着花花绿绿的图表。它的最高境界是“防火”,也就是提前预警和自动修复,而不是事后“救火”-7。
建立统一的可视化门户:别让运维人员每天在十几个不同的监控工具界面里切换。用Grafana这样的平台,把来自Zabbix、Prometheus、数据库、业务日志的关键指标,整合成几个面向不同角色(运维、开发、业务领导)的综合仪表盘。一眼看尽全局健康状态-1-6。
设计清晰的报警升级链路:报警不能乱响。根据严重程度(比如S1紧急、S2重要、S3警告)定义不同的通知渠道和响应人员。比如,核心数据库宕机(S1),直接电话呼叫值班架构师;单台应用服务器CPU偏高(S3),发个邮件或钉钉消息给运维小组即可-5。
推动形成故障闭环文化:每一次触发的报警,尤其是那些最终引起故障的,必须要有事后复盘。不只是解决就完了,要写故障报告,回答“为什么发生?”、“怎么发现的?”、“如何快速解决的?”、“怎样避免再发生?”这四个问题。这样,监控体系才能真正驱动系统和流程的改进-4-8。
未来已来:智能运维(AIOps)是方向
现在最前沿的,是给监控插上AI的翅膀。通过机器学习算法,对历史监控数据进行深度学习,可以实现:
异常检测:不用再手动设阈值了,系统自动学习正常模式,稍有偏离常态就能告警,更早发现潜在问题。
根因分析(RCA):当发生故障时,AI能快速关联分析同时出现异常的所有指标,给出最可能的根本原因定位,大大缩短排障时间。
趋势预测:根据历史增长趋势,预测磁盘将在多少天后写满、CPU负载将在何时达到瓶颈,从而实现容量预警,从容地提前扩容-7。
说到底,技术是冰冷的,但运维是有温度的。一套优秀的各种技术监控性能整理与实践,其终极目标不是创造更多的数据和屏幕,而是为了让研发兄弟们能睡个安稳觉,让业务稳定运行创造价值,让技术人的工作更有成就感和尊严。从今天开始,别再满足于支离破碎的监控视图了,动手梳理,建立起你的“千里眼”和“顺风耳”吧。这条路可能有点费劲,但走上去之后,你会发现,一切值得。