大家吼啊!今天咱们来唠点干的,聊聊现在这行当里最金贵也最让人头疼的玩意儿——算力。
特别是做AI这一行的兄弟姐们,估计都懂那种感觉:老板一句“这个模型赶紧跑一下”,你就得跟打仗似的去抢显卡。明明只需要跑个小实验,显存占用才几个G,结果得眼巴巴瞅着那张几十G显存的顶级卡在那儿睡大觉,旁边一群人排着队眼都绿了 -2。这感觉,就像你渴得要死,结果抱着个巨大的水缸却只能一滴一滴地接水,急死个人!
但这两年,事情悄悄起了变化。有一项技术,就像给这大水缸装上了水龙头和管道,让它变成了咱们屋里的“自来水管”,想啥时候接、接多少,随你便。这背后的推手,就是越来越聪明的 gpu演算技术。这玩意儿牛在哪?它不再让显卡傻乎乎地只干一种活,而是通过底层指令集的优化和资源的精细切分,让一块卡能同时干好几件完全不同的事儿,而且还干得贼快。
你可能会问,这跟我有啥关系?关系大了!以前咱们总觉得,显卡嘛,不就是跑跑深度学习、渲渲图?但现在的玩法早就变了。比如说,你打开淘宝或者抖音,推荐给你的东西为啥越来越懂你?这背后就是gpu演算技术在疯狂发力。它不是简单地算个乘法,而是用上了以前想都不敢想的复杂算法。有个叫“2-单纯注意力”的机制,专门让大模型像人一样去“理解”词语之间的复杂关系,而不是简单的一对一配对 -1。这玩意儿计算量爆炸,但靠着新一代显卡比如H100里头的硬件对齐设计,硬是把这种复杂运算的速度提上去了,甚至能直接调用专门的Tensor Core(就是显卡里头的超级加速器)来干活,效率杠杠滴 -1。

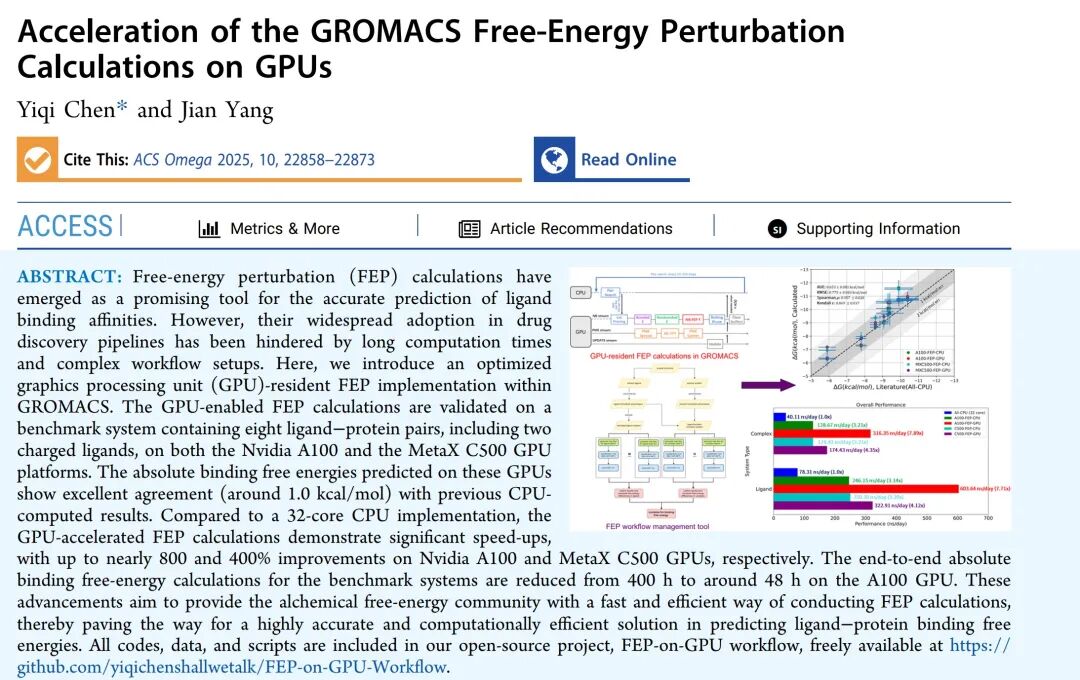
哎呀,说到这个我就想起前阵子帮一个搞生物医药的朋友调程序。他们做那个“自由能微扰”(FEP)计算,说白了就是模拟药跟病毒蛋白怎么结合,以前这是“金标准”但也慢得让人抓狂,跑一次实验够喝几壶茶的。为啥慢?因为这活儿以前主要靠CPU慢慢磨,显卡在旁边看着帮不上忙,急死个人!但现在不一样了,gpu演算技术直接把整个流程端到端地移植到显卡上跑,速度一下飙到原来的2.5倍 -10。我那朋友说,以前一周跑一轮,现在两天就能出结果,找药跟开盲盒似的,现在好歹能瞄一眼了。这不光是省时间,这是把整个研发的迭代周期给打穿了,你说吓人不吓人?
而且你发现没,现在的技术发展路子越来越“抠门”了,但抠得好!你看阿里云那帮人整出来的活儿,硬是把跑AI模型的GPU利用率从百分之三十几提到了快一半,用的法子贼聪明——在生成每个词(token)的时候动态决定要不要切换模型,就像炒菜时候大火爆炒和文火慢炖无缝切换,把显卡的每一分力气都榨干 -7。还有NVIDIA新出的Rubin CPX GPU,更绝,它把AI推理拆成两个阶段,用专门的卡干专门的活,一分工配合下来,吞吐量能飙到6倍 -4。这就好比原来是一个全能运动员啥都干,现在改成接力赛,每人跑自己最擅长的那一棒,成绩能不好吗?
说到这,我又想起个事。很多人以为显卡牛就牛在硬件,其实不然,那藏在软件里的“兵法”才是真功夫。比如NVIDIA Hopper架构里加的那套DPX指令,专门对付那些动态规划问题。啥是动态规划?举个不恰当的例子,就像快递小哥要送一百个地方,怎么走最短?这算法复杂得很。但有了DPX指令,处理这种问题的速度能比以前的卡快上40倍 -8。40倍啊兄弟们!这不光是跑得快,这是把以前理论上可行、但实际没法落地的事儿,硬生生给干成了现实。比如基因组测序,以前要等半天,现在可能喝杯咖啡的功夫就分析完了,对精准医疗的推动不是一星半点 -8。
再说个接地气的,咱们平时用XGBoost跑个表格数据,数据量一上去,内存就爆了。结果现在NVIDIA整的那个Grace Hopper超级芯片,配合新版的XGBoost 3.0,居然能直接在单个芯片上搞定TB级的数据训练,速度比纯CPU的服务器快8倍 -9。你想啊,以前要搞这么大数据的,得上分布式集群,又麻烦又贵。现在好了,一块芯片搞定,这不就是“把大象装进冰箱”的科技树被点亮了吗?更绝的是优刻得那套虚拟化技术,把显存和算力像切蛋糕一样精细化切分,想切多细切多细,还能做到几乎没性能损耗 -2。这对咱们这些经常要跑小实验的算法狗来说,简直是福音啊,再也不用眼巴巴排队等显卡了。
所以说,别再把显卡只当成一个简单的计算工具了。现在的gpu演算技术,更像是一个会自己动脑子的超级工厂。它不仅在硬件上堆料,更在软件和算法层面玩出了花:有的负责把复杂运算拆解成适合流水线生产的步骤 -1;有的通过异构计算,让CPU和GPU无缝配合,各自干最擅长的活儿 -6;还有的通过池化技术,让算力像水电一样随用随取 -7。甚至连国产的沐曦GPU,也在药物研发这种高精尖领域追了上来,用软件技术的先进性来弥补硬件的不足,在分子动力学模拟上实现了对传统CPU的降维打击 -10。
最后分享点个人感受吧。以前调程序,老得琢磨怎么给显卡“减负”,生怕它算不过来。现在反过来了,得琢磨怎么给它“找活干”,怎么把它的潜力全榨出来。就像上海交大那个团队做的求解器,能把铁路排班时间从几天压缩到20分钟 -5。这不光是快,这是让以前不可能的事变成了可能。技术的魅力就在于此,它不断推高上限,把那些横亘在科学家、工程师面前的“算力墙”一点点敲碎。
所以,下次当你再跑起一个程序,看着显卡风扇呼呼转的时候,你可以想想,在这小小的芯片里,可能正上演着几十种甚至上百种不同的“兵法”,它们协同作战,只为了让你看到结果的那一刻,能少等那么几秒。这种感觉,挺奇妙的,不是吗?