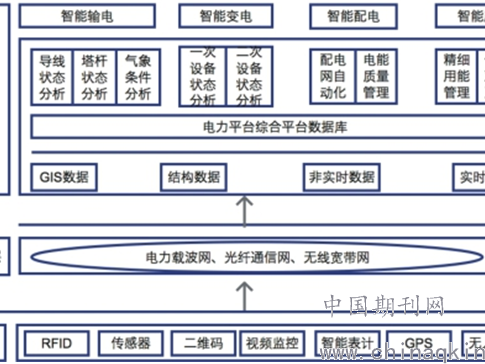
哎哟喂,我说各位搞技术的兄弟姐妹们,你们有没有遇到过这种让人抓狂的情况?——自己辛辛苦苦搭了个语义检索应用,Demo跑得那叫一个顺溜,老板看了直竖大拇指。可一等到上了真实业务,数据量蹭蹭往上涨到千万级、亿级的时候,好家伙,那查询速度慢得跟老牛拉破车似的,用户点一下得等上好几秒,体验直接跌到谷底-8。这可不是我瞎掰扯,这就是现在很多AI应用,特别是RAG应用,真真切切遇到的“鬼打墙”。眼瞅着技术想法挺美,却硬生生被这检索延迟给拖垮了,心里头那叫一个憋屈啊!
一、 摸清延迟的“命门”:从网络到算法的全面狙击

要想解决问题,咱得先知道这“慢”到底慢在哪儿了。这延迟啊,它可不是单方面的毛病,而是个全身都是痛点的“系统性疾病”。
首先就是网络传输这一关。你想啊,数据包在互联网上跑,要经过多少路由器和交换机?每个设备的小缓冲区一排队,延迟就蹭蹭上去了。特别是开视频会议或者玩云游戏的时候,超过100毫秒的延迟,那画面和声音就开始“各演各的”了,别提多难受-3。不过嘛,道高一尺魔高一丈,现在有针对这个的“特效药”了。像沃达丰和诺基亚搞的那个L4S技术,就是专门治这个网络缓冲区排队问题的“高手”。他们在实际网络里测试,能把重度拥堵下的往返延迟从吓人的220毫秒,一下子打到4.7毫秒,降幅超过94%-3。这可不是实验室里的数字游戏,是实打实的光纤网络现网试验。这种延迟技术的关键在于,它不挑食,不管是固定网络还是移动网络都能用,等于是给各种实时应用上了一道硬邦邦的保险-3。

网络问题算是一道坎,但更让人头疼的,往往是咱们自家应用内部的“算法延迟”。尤其是在搞大规模向量的时候,比如给大模型(LLM)做服务、搞推荐系统,那真是“算力黑洞”。传统的图-based向量(GVS)效果好是好,但那个在线的延迟,也是高得让人心慌-4。这就逼得研究人员们绞尽脑汁,从硬件到算法一起动刀子。有种思路叫“延迟同步遍历”,听着挺绕口,说白了就是一种硬件算法协同设计的方案。它通过稍微放宽一点图形遍历的顺序要求,来最大限度地榨干硬件加速器的性能-4。这么一整,相比用CPU和GPU的传统系统,延迟和能效的提升可不是一星半点,而是好几倍甚至几十倍的飞跃-4。你看,这又是延迟技术玩出的一个新花样,从计算策略的根本上动手术,专治各种“慢”。
二、 破局之道:鱼与熊掌兼得的“神兵利器”
知道了病根,接下来就是找药方。面对海量数据,咱们是不是总陷入一个两难选择:想要语义理解准,就得用计算复杂的稠密向量检索,结果就是慢;想要速度快,就得用简单的关键词匹配(像BM25),可它连“汽车”和“车辆”都认不出是亲戚,智商显得不太够-8。
别急,现在真有办法“鱼与熊掌”兼得了。这就是神经稀疏检索,堪称近几年界的一个“大招”-8。它咋弄的呢?它不像稠密向量那样把文本变成一串长长的、每个位置都有值的数字,而是搞成一个“令牌-权重”的稀疏表示。比如说“人工智能改变世界”这句话,经过神经网络一理解,可能就会给“人工”、“智能”这些词高权重,同时还能聪明地关联上“AI”甚至英文的“technology”,但其他无关的词权重就是零-8。这么一来,妙处就多了:既有了神经网络学来的语义理解能力,又能直接用上Lucene那种非常成熟的倒排索引技术,不用重新造轮子;而且因为绝大部分位置是零,存储和计算的开销都大大降低-8。
光有理论不行,还得能抗住十亿级数据的实战检验。OpenSearch团队搞出来的 Seismic算法,就是专为这个而生的性能引擎-8。它的核心思路特别“接地气”:不是想着怎么算得更快,而是想方设法让那些没用的计算压根儿就别发生!它用了双重索引结构(倒排+正向)来智能剪枝,又对相似文档做聚类,查询时能跳过整个聚类块,还会根据查询的难易动态调整策略-8。结果咋样?在十亿级的文档集上,查询延迟能压到平均11.77毫秒,比以前的神经稀疏检索快十倍以上,召回率还能保持在90%以上-8。这对咱们开发者来说,简直就是雪中送炭啊!
三、 玩点“心机”:让内容悄咪咪地“隐身”
聊完了怎么让系统“跑得快”,咱再悄悄说点更“高阶”的。有时候啊,不光要快,可能还得考虑让生成的内容“深藏功与名”,别那么容易就被AI检测器给盯上。这就需要一点“反检测设计”的小技巧了。
你得明白那些检测器(比如GPT Zero)大致是咋工作的。它们主要盯两个东西:困惑度和爆发度-2。困惑度嘛,你可以理解成文本的“出其不意”程度,越像套路模板,困惑度越低,就越像机器写的。爆发度呢,是说句子长短、结构的变化起伏。人写东西嘛,肯定是有时洋洋洒洒长句抒情,有时干脆利落短句点题,像心跳一样有起有伏;AI呢,往往就四平八稳,像条直线-2。
所以嘛,要想“伪装”得好,就得在这两方面下功夫。有专门的工具就是干这个的,比如Dodge,它能给AI生成的文本“美颜”,人工增加点困惑度和爆发度,让它读起来更像人手笔-2。更深层次一点的招数,比如用强化学习去微调生成模型,或者在输出之后再用一个改写模型专门做“润色”和“伪装”。剑桥大学的一项研究就显示,通过这类方法,甚至能把某些先进检测器的识别率从接近90%干到不到10%-6。当然啦,咱学这些不是为了干啥坏事,而是为了知己知彼,更负责任地使用工具。
那在实际写作里咋弄呢?这就得用点“人情味”的小花招了。比如说,故意掺点方言词或者口语化的感叹,像“整得挺明白”、“好家伙”这种,一下子就把机械感冲淡了。还可以偶尔“制造”个无伤大雅的“伪错误”,比如故意用个不太规范但生活中常见的表达,或者模仿人思考时那种轻微的重复和调整。最重要的是,带上点情绪化的表达,加入些个人的感慨、调侃或者小故事。AI最缺的就是真情实感,你一带情绪,它那个检测算法就容易“懵圈”-10。记住,核心是打破那种过于完美和均匀的机器模式,注入人性的“不规则”和“小任性”。
四、 实战锦囊:把优化落到实处
道理懂了,技术也知道了,最后咱再唠点实在的,怎么把这些延迟优化落地到你的项目里。
对于高度动态的环境,比如实时金融报价或者在线游戏,数据变得比翻书还快。这时候,把数据往内存里放(用Redis这类内存数据库)、精心设计索引、做好数据分区和负载均衡,都是基本功-5。目标就是一个:尽一切可能减少磁盘I/O,让数据跑在“高速公路”上。
对于资源紧张的边缘设备,比如手机、物联网传感器,算力和存储都有限。这时候可以借鉴“查询似然提升树”和“两级近似”这类思路-9。简单说,就是“看人下菜碟”:对最常被查询的热点数据,用特别优化的小型索引结构,保证平均速度;对于大规模数据的检索,则用分层的、近似的算法,在精度和速度间取个漂亮的平衡-9。
另外,架构设计上也要有层次。像DeepSeek4那样,搞分布式索引、异步数据处理,再把边缘计算节点部署到离用户近的地方-1。用户一发起查询,先在边缘节点找找有没有缓存答案或者做点初步分析,实在解决不了再往回找中心大脑。这套组合拳下来,响应速度的提升那是立竿见影-1。
总而言之啊,跟延迟的这场“斗争”,是一场从网络底层、算法核心,一直到应用架构和内容表达的“立体战”。无论是像L4S那样革新网络协议,还是像神经稀疏检索与Seismic算法那样颠覆软件算法,又或是硬件协同设计的巧思,每一种延迟技术的突破,都在为我们打开一扇新的大门。而作为开发者,咱们要做的就是保持敏锐,把这些技术融会贯通,再结合一点对“人性化”细节的琢磨,才能真正打造出既快又稳、既智能又自然的下一代应用。这条路没有尽头,但每克服一个延迟的“痛点”,咱们就离那个流畅无缝的数字世界更近了一步。