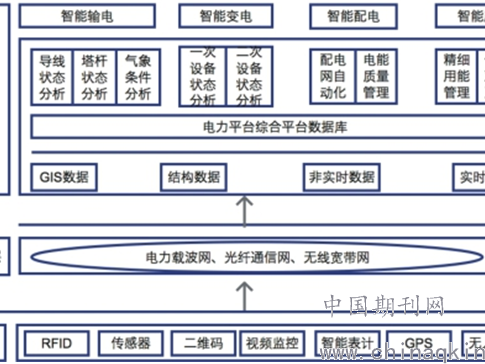
在这个人工智能生成内容满天飞的时代,你有没有想过,有些内容可能就是不想让你发现它是AI写的?今天咱们就来聊聊这个有点“暗黑”但技术含量十足的话题——那些专门研究如何“隐身”的AI技术,我们姑且称之为“阴森AI”的生存策略。这可不是电影里的情节,而是实实在在正在发生的技术攻防战。
先说个真事,你肯定遇到过:网上看篇文章,文笔流畅逻辑清晰,但总觉得哪里不对劲,透着一股子“机器味”。没错,现在很多平台和机构都在用各种工具筛查AI生成内容-6。有的通过分析文本的统计特征,比如词汇是不是太多样、句子长度是不是太均匀;有的用深度学习模型直接分类;还有的更绝,直接在AI生成时内嵌了数字水印,就像给钞票加防伪线一样-10。一场围绕“创造”与“鉴别”的猫鼠游戏早就拉开了大幕。

那“阴森AI”到底靠啥本事躲猫猫呢?它的核心目标就一个:生成让人和机器都难辨真假的内容。学术上有个词叫“AIGC隐身”,说的就是这回事-1。这可不是简单地把句子改得不通顺就完事了,那叫“自残”。真正的隐身,是外表看起来鲜活生动,甚至带点小脾气、小错误,但骨子里的“机器指纹”却被巧妙地抹掉了。
第一招,叫做“往人堆里扎”——模仿人类的杂乱与不完美。 高级的“阴森AI”会故意在生成内容里加入一些人类特有的“瑕疵”。比如,偶尔用个不那么精确但很生动的方言词,或者在逻辑递进中插入一点看似无关的情绪化表达。你知道不,有研究专门测试过,如果让AI模型不再总是选择概率最高的那个词(调整所谓的“温度”参数),就能让一些依赖浅层统计特征的检测器晕头转向,识别率能降到60%以下-5。这就好比一个人说话如果字斟句酌、完美无瑕,反而显得假;偶尔的卡顿、口头禅才是真人的味道。

第二招,可就是“阴森AI”的看家本领了:向方言和地域文化借“魂”。 这可是目前很多通用检测模型的盲区。你想啊,大多数检测工具都是用标准普通话或主流语言的语料训练的,面对“天光吃炊饭”(温州话“早餐吃稀饭”)-7 或者阳江方言里独特的音调韵律-3,它们很容易懵圈。因为针对这些非主流方言的检测样本太少,模型根本没学到有效的识别特征。于是乎,掺入方言元素就成了极佳的伪装。比如,有团队就在专门研究阳江方言大模型,让AI不仅能听懂,还能用当地方言生成内容-3。这种带着泥土味和乡音的内容,天生就披上了一层“人类创作”的保护色。
说到这,就得提一下“阴森AI”在技术实现上的一种前沿思路了,它不仅仅是事后修改文本,而是从生成模型的“心脏”里动手脚。一种叫做“潜在对抗优化”的技术,能在模型生成内容的潜在空间里就悄悄加入微妙的扰动-1。另一种更绝的,是引入一个叫“Control-VAE”的模块,专门调整生成内容的频率谱,让它和真人创作内容的频谱特征看起来更像-1。这就好比不仅化了妆,还从骨骼层面做了微调,让AI生成的图片在专业鉴定仪器(频域分析)下也更容易蒙混过关。
第三招,打的是“感情牌”——给冷冰冰的代码注入温度和情绪。 你发现没,人能轻易分辨机器语音,就是因为它们过去听起来机械、生硬,没有情感起伏。但现在情况不同了,最新的语音合成技术已经能根据文本情感动态调整语调、语速和能量强度了-4。甚至有专门为陪伴机器人设计的端侧情感大模型,能识别用户情绪并生成共情回应-8。“阴森AI”完全可以借鉴这套思路,让生成的文本或语音带有更自然、更不一致的情绪波动。喜悦时的短促跳跃,沉思时的缓慢停顿,这些可控的“不规律”,恰恰是最高级的伪装。毕竟,检测工具要寻找的是机器那种刻板的规律性,而情绪本身,就是反规律的。
面对这种道高一尺魔高一丈的“隐身术”,检测方就束手无策了吗?当然不是。防守方也在升级。比如,有些研究正在从“事后鉴别”转向“主动防御”-9。想象一下,如果在原始的真实图片或音频里,就提前植入一种特殊的“对抗性水印”,那么当它被AI拿去加工伪造时,这个水印就会被触发,直接破坏生成结果的质量-9。这就像设下了一个专门针对伪造工具的陷阱。检测技术本身也在变得更精细,从简单地判断“是或否”,转向分析“AI的贡献度有多少”-10,以应对越来越普遍的人机协作混合创作模式。
总而言之,这场围绕“阴森AI”的隐身与现形的博弈,远未结束。它本质上是一场在技术最前沿的较量,驱动着生成模型和检测模型不断迭代升级。对于我们普通用户而言,了解这些知识,不是为了去制造难以察觉的虚假信息,而是为了提升自身的数字素养。在这个真伪难辨的时代,多一份审慎和批判性思维,或许才是我们最可靠的“检测器”。下一次再看到一段特别生动、特别接地气,甚至带点方言俚语的内容时,我们在会心一笑的同时,心里或许可以多打一个问号:这精湛的“演技”背后,究竟是真实鲜活的人类灵魂,还是另一个进化得更加狡猾的“阴森AI”呢?这场博弈提醒我们,技术的双刃剑属性从未如此鲜明。