不知道你发现没有,这两年不管是刷短视频还是看新闻,总能看到一些美得不像话或者怪得让人发笑的图片,底下标注着一行小字:“由AI生成”。你自个儿上手玩的时候,有时候键入了自以为很详细的描述,出来的东西却跟你心里想的隔着一万个像素的距离。那种感觉就像是,你明明想吃一道宫保鸡丁,结果厨房给你端出来一盘西红柿炒蛋,虽然都是菜,但味儿全不对。
这时候你可能就在心里犯嘀咕:这AI作画的原理神经网络里头到底在搞啥子名堂?它咋就听不懂人话呢?
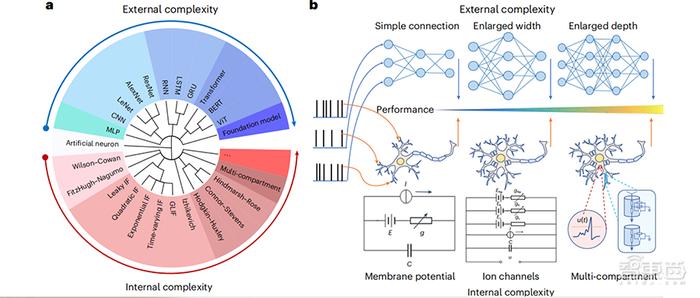
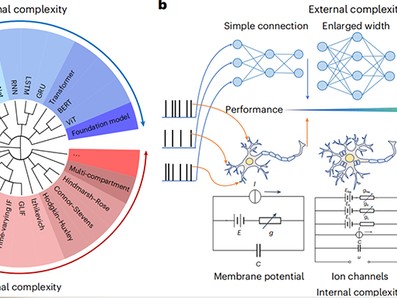
其实这事儿吧,真不能全怪AI笨。咱们今天就来絮叨絮叨,把AI那个“脑子”掰开了揉碎了,看看它到底是咋琢磨事儿的。注意看哈,这里头门道多得很,搞懂了这些,你以后用起来才能拿捏住它。
首先你得明白,AI画画压根儿就不是像咱们人类一样,从一张白纸开始,一笔一笔勾线、上色。它的工作方式,特别像一个特别有耐心的雕塑家,干的活儿叫“去芜存菁”。但这个雕塑家面对的不是一块石头,而是一整块密密麻麻的电视雪花噪点。AI作画的原理神经网络最核心的一步,就是要学会从这一堆乱糟糟的噪点里,通过一层一层的计算,把你要的那个东西给“捞”出来。
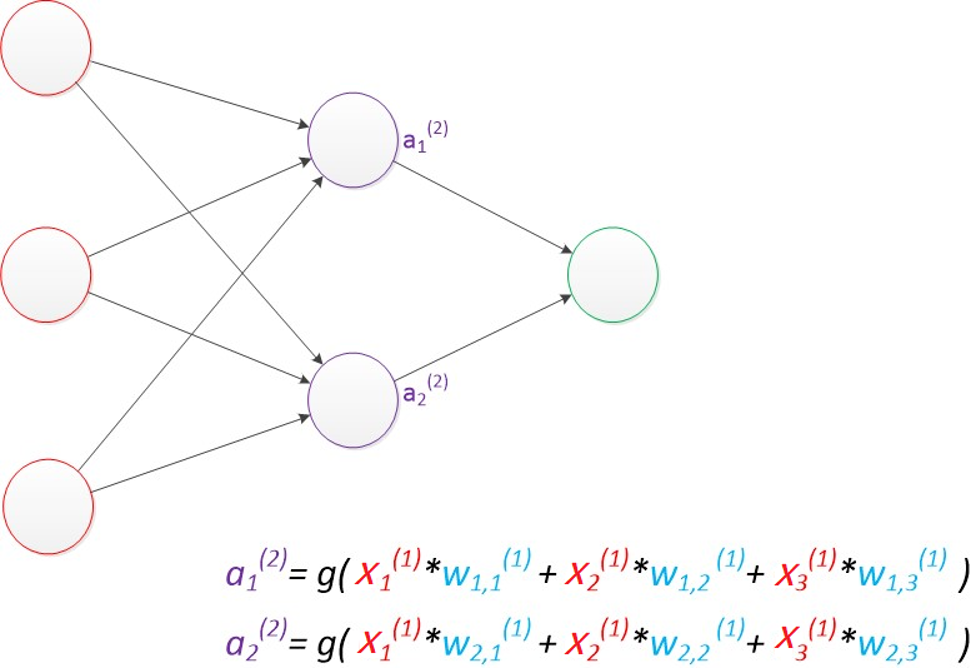
这个过程在科学界有个专门的名词叫“扩散模型”-5。你可以这么想象:我给你一张清晰的猫咪照片,然后我不断地往这张照片上撒胡椒粉(也就是噪点),撒了一遍又一遍,直到这张照片完全被胡椒粉覆盖,变得模模糊糊啥也看不清。AI在训练的时候,就是反复观看这个“从清晰到模糊”的过程,并且死死记住每一个阶段的样子。等它学成出师了,你给它一张全是胡椒粉的图,它就能反着来,一步一步地把胡椒粉去掉,还原出本来清晰的图像-5。这就像你玩拼图,虽然盒子里的碎片是乱的,但你见过原图是啥样,所以你知道该咋拼。
不过光会去噪点还不行,你得给它个方向啊。你输入的那句话,比如“一只穿着汉服的猫”,就是指挥棒。你这句话会先被拆解成一个个的“密码”(术语叫Token),然后通过一个叫“文本编码器”的东西,变成AI能看懂的数学指令-5。在AI一层层去除噪点的过程中,这个指令就像个拿着小鞭子的监工,一直在旁边喊:“歪了歪了,那个袖子不够飘逸!眼睛再给我画圆一点!”AI作画的原理神经网络里头的玄机就在这里——它不仅仅是看图说话,而是在每一个步骤里都在做数学题,计算怎么让当前的图像跟你的文字描述无限接近。
我跟你讲,有时候看到网上那些大神出的图,那细节,那光影,真的绝了。比如去年全运会开幕式上那个174米的AI数字画卷,好家伙,把整个大湾区的地标和岭南山水全画进去了,既有油画的厚重,又有数字艺术的灵动-3-7。那个背后用的就是更先进的卷积神经网络和扩散transformer架构,能把上万幅中西方油画的笔触、色彩特征都提炼出来,然后揉吧揉吧,形成自己独特的“数智笔触”-3-7。你要是没点耐心,没搞懂这里头的道道,光靠运气去抽卡,一辈子也抽不出那种级别的作品。
再往深了说一点,其实这里面还分“流派”。有些AI它是个“模仿大师”,专门学梵高的《星空》那种笔触。这技术叫“神经风格迁移”-4-6。它用卷积神经网络把你照片里的内容(比如你家的狗)和名画里的风格(比如莫奈的睡莲)硬生生糅合在一起。这时候,网络里不同的层负责不同的活儿:浅层的看边缘纹理,深层的看物体形状-4-6。这就像你临摹字帖,既要把握字形(内容),又要模仿笔锋(风格),两边都得兼顾,最后出来的东西才有那个味儿。
但是哈,你也别把AI想得那么神。它其实就是个“最笨的聪明人”。它不懂什么叫美,什么叫意境,它只知道像素和概率。有时候你让它画手,它给你画出六根手指头,因为它见过的手大多是这样的,它没法理解“人类只有五根手指”这个生理常识。这时候你就得反思,是不是你给的那个“监工”(提示词)不够给力?是不是你没告诉它“画一个合理的手”?
所以说,要想让AI听你的话,关键得你自己先懂点门道。比如现在很多人玩的那个LoRA模型,就是一种给AI“加餐”的方法-8。你想让AI画某个特定的角色或者某个固定的风格,不用把它整个脑子都洗一遍,只需要在它原有知识的基础上,给它吃一点小灶,用少量的图片调整它的几个关键参数(也就是低秩适应)-8。这样训练效率高,出来的图还特别贴脸。这就像教一个钢琴家弹一首新曲子,不用从指法教起,只需要给他谱子,他稍微练练就能弹得飞起。
现在技术的发展快得很,已经不满足于只画平面图了,开始往3D使劲。以前做个3D模型,得先建个白模,再把贴图糊上去,麻烦得很,还容易错位。现在的新模型,比如Neural4D-2.5,讲究的是“感生一体”,在生成的一瞬间,几何结构、纹理颜色、物理属性就一块儿长出来了-9。这就厉害了,生成的模型表面干净通透,再也不用担心贴图跟鬼影似的糊在一起-9。
说到底,ai作画的原理神经网络听起来高大上,其实就像训练一个新入职的美工。你得告诉他需求(提示词),他得具备基本功(预训练模型),遇到复杂的活儿还得让他翻翻参考书(LoRA微调)。只不过这个美工精力旺盛,一秒钟能出几百张草图,但审美嘛,有时候就有点不在线,需要你这个当师傅的不断调教。
你看,当你知道了它是在“一步步从噪点里还原图像”,知道了它是通过“卷积核”在提取特征,下次你再输入“赛博朋克风格的老北京胡同”时,脑子里大概就能浮现出那个画面形成的过程:那些霓虹灯的颜色是如何被一层层渲染上去,那些青砖的纹理又是如何被保留下来。这样一来,你跟AI之间就不是简单的命令与服从,而是一种基于理解的协作。你负责创意和审美,它负责把那些琐碎的像素拼凑起来,这感觉,嘿,还真不赖。