

你有没有遇到过这种让人出戏的时刻?看一段数字人讲解视频,声音倒是字正腔圆,可那嘴型张合总感觉慢半拍,或者僵硬得像在嚼蜡,明明说的是激动的事,脸上却一副“莫得感情”的样子。更别提那些跨国影视剧,配音和演员原声口型对不上,简直逼死强迫症。这些尴尬,说到底都是“口型同步”这门老手艺跟不上了新时代的需求。
不过啊,这些让人头疼的视觉与听觉分裂症,如今正被一股强大的技术浪潮席卷而改变。这就是我们今天要聊的AI生成口型技术。它可不是简单地把嘴巴动画和声音波形对上就行,而是让AI深度理解语音里的每一个音符、每一缕情绪,然后驱动虚拟面孔做出从唇齿开合到眉梢波动的全套自然反应-1-4。

从“手动对帧”到“AI驱动”:一场效率的解放
过去,要让动画角色或者虚拟人开口说话,那可是个苦差事。动画师得盯着音频波形,一个音素一个音素地手动绘制对应的口型,一分钟的对话可能就得花上好几个小时-5。这不仅是时间和金钱的燃烧,更成了创意生产的瓶颈——想改句台词?得,全部重画。
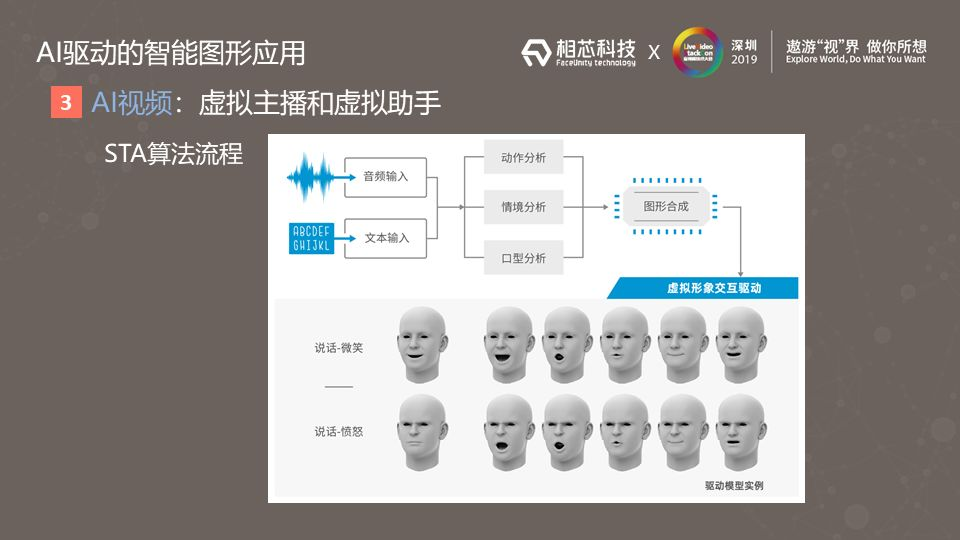
AI生成口型技术的出现,就像给这个行业装上了自动变速箱。它的核心是让机器学会“听音辨形”。AI模型,比如经典的Wav2Lip,会像一位顶尖的语言学家兼动画师,仔细分析音频中的辅音爆发、元音共振峰等特征,然后精准预测出面部68个关键点应该如何运动,从而生成毫无违和感的唇部动画-4-5。这样一来,制作效率提升了数倍,成本大幅降低,让创作者能把精力真正集中在故事和角色塑造上-5。
不止于嘴唇:从“对口型”到“全身心表达”
但很快,人们发现只动嘴巴是远远不够的。一段充满激情的演讲,如果说话者身体僵硬、面无表情,那效果绝对大打折扣。早期的技术就陷入了这种“口型僵局”-3。真正的沟通是全身心的,我们的表情、手势、头部微倾都在传递信息。
于是,技术的进化方向从“口型同步”迈向“全身动作同步”。最新的AI生成口型框架,思考的已经不仅仅是“发这个音时嘴巴该什么样”,而是“这段充满情感的语音,应该对应怎样一套连贯的面部表情和肢体语言”-3。例如,一些先进模型会采用“稀疏帧引导”的生成范式-3。它们不再一帧帧死板地复制原视频,而是聪明地选取少数关键帧作为身份和风格的锚点,然后在AI的“自由发挥”下,根据音频的韵律和情感,生成自然而协调的头部转动、眉毛微挑甚至手势变化-3。这让虚拟人的表达瞬间有了灵魂,从机械的“发声机器”变成了有感染力的“交流者”。
挑战与未来:更真实,更实时,更普惠
尽管进步神速,但这条路还没走到尽头。当前的AI在处理一些极端夸张的表情,或者仅凭很少的样本学习一个新角色的说话特点时,仍然会有些力不从心-5。而且,如何让这项技术不仅在强大的云端服务器上运行,还能“飞入寻常百姓家”,在每个人的手机或普通电脑上实时、流畅地驱动虚拟形象,也是研发的重点-1。
未来的画卷正在展开。趋势已经指向了多模态大模型的深度融合-1。想象一下,AI不仅能听懂你在说什么,还能通过语音的细微差别判断你是高兴、悲伤还是愤怒,从而自动匹配生成细腻的微表情——比如开心时眼角的皱纹,惊讶时瞳孔的微微放大-1。与此同时,像英伟达Audio2Face这样的开源工具正在降低技术门槛-6,而像SyncTalk++这类研究则在追求高达每秒101帧的超高渲染速度与极致真实的结合-2。一场由AI驱动的表达革命,正在虚拟世界与现实世界的边缘热烈发生。
所以,下一次当你看到一个虚拟主播对你侃侃而谈、神情生动时,或许可以会心一笑。你知道,这背后不再是动画师无尽的苦工,而是一个正在不断学习、进化,致力于让每一次数字沟通都“声情并茂”的AI。它正默默修补着那些曾经让我们出戏的缝隙,让虚拟与真实的边界,在每一次自然的唇齿开合间,逐渐模糊。






