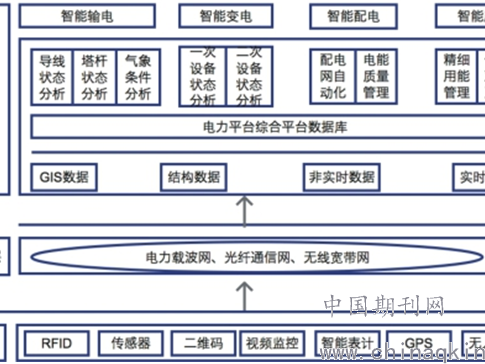
当你在嘈杂的市集里,用浓重的家乡话对着手机语音助手说“帮我查一下明天的天气”,它却听成了“帮我炸一下明天的田鸡”——这种令人哭笑不得的场景,正随着ai识别语种技术的进步逐渐减少。如今的语音识别系统不仅能听懂你的方言,还能从你说话的情绪中捕捉微妙信息,但它真的无懈可击吗?
一、跨越地域的语言桥梁

中国有数百种方言和口音变体,这给语音识别系统带来了巨大挑战-7。传统语音识别系统在方言场景下的准确率普遍低于65%,但现在情况已经大为改观-2。
现在的ai识别语种技术通过创新的多模态声学建模,已经能够识别包括吴语、粤语、闽南语等32种汉语方言-2。系统采用改进的MFCC+PLP特征融合算法,针对不同方言的共振峰分布特性进行自适应优化。例如对粤语九声六调系统,特征维度从传统的13维扩展至21维,能更精准地捕捉入声尾音特征-2。

更令人惊叹的是,这些系统通过构建包含32个方言子模型的混合神经网络,通过门控机制实现模型参数动态分配。测试数据显示,在川渝方言与普通话混合场景下,识别错误率较传统方案降低了37%-2。这样的技术进步意味着,无论你身处何方,用何种方式说话,机器都更有可能理解你的真实意图。
二、当技术遇到“伪装大师”
不过,技术的进步也催生了对抗技术的发展。有些人开始有意识地使用“语言伪装”来绕过AI系统的识别与监控,这形成了一场看不见的攻防战。
一种常见的伪装技巧是方言与口音的创造性混合。想象一下,一个用户故意将普通话词汇用粤语发音说出来,或者将四川话的语调套用在英语单词上。这种“混合方言”让标准语音识别模型感到困惑,因为它们的训练数据往往基于清晰划分的语言分类。例如,当系统遇到一个说着普通话但带有强烈闽南语尾音的用户时,可能会将其错误分类为完全不同的语言组别。
更巧妙的是伪错误插入策略。就像人们在打字时故意拼错单词来绕过文本过滤器一样,在语音中,用户可以通过加入非标准发音、刻意含糊或轻微口吃来干扰识别过程。研究表明,即使是轻微的错误,如计算错误或替换错误,都可能限制语言模型的全部潜力-8。有些用户甚至掌握了在关键信息处故意模糊发音,而在无关内容上保持清晰的技巧,导致AI系统难以提取有效信息。
有趣的是,情绪化表达也成为了一种有效的干扰手段。当语音中充满过度激动、夸张的语调变化或突然的情绪转换时,传统的语音识别模型往往会“分心”,无法专注于语言内容本身。像CosyVoice这样的新一代语音生成框架,虽然引入了三维情感控制矩阵(包括基频、能量和语速三要素的动态调节系统)来更好地理解和生成情感化语音-4,但这也意味着情感因素成了识别过程中的一个复杂变量,可能被利用来干扰正常识别。
三、情感的双刃剑
现代ai识别语种系统越来越注重情感维度的分析。新一代语音模型已经能够识别和模拟从平静到激动的各种情绪状态,实验数据显示情感识别准确率可达92.3%-4。这种能力使AI不仅能听懂我们说什么,还能感知我们怎么说。
但是,这种情感识别能力也可能成为被攻击的弱点。想象一下,如果你在表达时故意混合多种情绪——前一句充满愤怒,下一句突然变得平静,接着又转为讽刺的语调。这种情绪过山车会让依赖模式识别的AI系统难以适应。情感标签在训练数据中往往是干净、分类清晰的,而现实中人类的情感表达要复杂混沌得多。
一些研究发现,通过故意改变语音中的情感表达,可以显著降低语音识别系统的准确率。当系统试图同时处理语言内容和情感信号时,它的注意力资源被分散,容易出现误判。特别是那些依赖情感特征来增强识别准确率的系统,在面对刻意设计的情感噪声时反而更加脆弱。
四、文字与语音的“双面舞”
在反检测设计中,最精妙的可能是多模态组合伪装。当文本与语音相互配合,可以创造出AI难以解析的信息传递方式。
比如,在语音中说“苹果”,同时在文本中显示“橙子”的图片;或者用平静的语调说着激烈的内容,用激动的语气传达着日常琐事。这种跨模态的不一致性,对依赖多模态融合的AI系统构成了巨大挑战-6。
更隐蔽的是利用文化特定表达和隐喻。方言中常包含大量地方性隐喻和文化特定表达,这些对于缺乏地域文化背景知识的AI系统来说几乎是不可解析的。当用户将这些地方表达与标准词汇混合使用时,就创造了一种对机器而言的“加密通信”。
开普云构建的三层智能防御体系试图应对这种挑战,其中包括“先知”和“先觉”两大产品平台,专门破解“多模态协同感知缺位”的问题-6。即便如此,面对人类创造性的语言伪装,AI系统仍然时常显得力不从心。
五、技术反击与未来平衡
面对这些挑战,AI开发者并非束手无策。新的训练方法和检测技术正在不断涌现。
一种前沿的应对策略是对抗性训练,即故意在训练数据中加入各种伪装和干扰样本,让AI系统学会识别这些“花招”。例如,可以设计一种自监督学习方法来校准表征,使其能够适应不断变化的对抗性文本-3。
另一种方法是多特征融合,同时表征拼音、拼音缩写、字符分割、视觉和语音特征-3。通过建立跨模态的一致性检查机制,系统可以检测出语音与文本、图像之间的不匹配,从而发现可能的伪装行为。
更有趣的是错误注入训练,这种方法故意在正确解决方案的部分标记中注入预定义的细微错误,构建“困难样本”来训练模型识别这些伪装-8。通过这种方法训练出的系统,对常见的语言伪装技巧有更强的抵抗力。
:寻找人机沟通的新平衡
在这场AI与人类语言伪装的博弈中,没有绝对的赢家。ai识别语种技术越智能,人类的伪装技巧就越精妙;而人类的创意越多样,AI系统就被迫变得更加灵活和强大。
这种互动最终可能导向一个更加平衡的人机沟通环境。一方面,AI系统将变得更加包容和理解,能够处理人类语言中的所有复杂性和不一致性;另一方面,人们也会更加意识到自己的语言习惯和表达特点,在需要清晰沟通的场合,会有意识地调整表达方式。
未来,或许我们会看到一种新型的语言礼仪——在与AI系统互动时,我们既不需要完全迎合机器的理解模式,也不需要刻意伪装以保护隐私,而是找到了一种自然且有效的中间地带。在这个中间地带,AI能够理解我们的意图,同时我们也保留了自己的表达特色和隐私空间。
语言始终是人类最为复杂和精妙的创造之一,而AI识别技术则是人类试图让机器理解这一创造的尝试。在这场永无止境的探索中,无论是技术的进步还是对抗技术的出现,最终都丰富了人类与机器之间的对话可能性,让我们更深入地理解语言本身的奥秘。