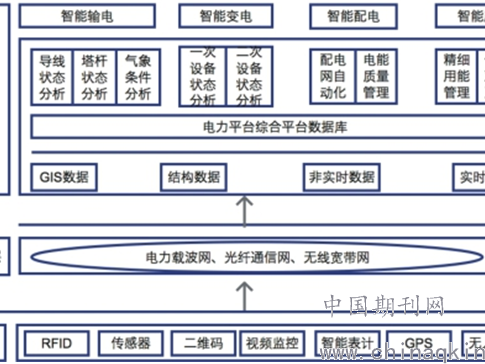
前几天刷视频,瞅见个动画老爷子用一口地道的川普讲笑话,眉毛一挑一挑,嘴巴开合跟真人似的,连说“巴适得板”时那个得意的嘴角弧度都一模一样。我盯着屏幕愣了好半天,心里直犯嘀咕:这玩意儿,真的是电脑做出来的?现在的技术已经这么邪乎了吗?
后来我一琢磨,这大概就是现在大家常念叨的“人声动画AI”整出来的好活儿。说白了,这技术就是让虚拟人或者动画角色,不光能发出声音,还能根据说的内容,实时做出匹配的口型、表情甚至肢体动作-2。你想啊,以前看动画片,尤其是引进的外国片,经常能感觉配音和口型对不上,看着就别扭。现在好了,有了这项技术,不管你说普通话、英语,还是四川话、粤语,屏幕上那位都能严丝合缝地对上嘴型,连叹气、笑出声儿这样的细节都能用表情给你带出来-4。

从“哑巴”到“声情并茂”:关键就在同步
这项技术最核心、也最让人头疼的难点,就是怎么让声音和画面“步调一致”。你想想,咱们人自己说话,大脑指挥嘴巴,那是天生的同步。可对AI来说,它得先听懂语音里的内容、语气、停顿,再把这些信息瞬间转化成一大堆控制面部肌肉运动的参数,最后生成连续自然的画面。这里头差一丝一毫,看起来就会觉得“假”-5。

早些年,科学家们为了攻克这个问题,路子可没少走。最早的办法有点像“看图说话”的反向操作,比如Speech2Vid这种模型,它尝试直接把声音和一张静态人脸照片扔进一个复杂的网络里,希望能直接“蹦出”一段说话视频。想法挺大胆,但效果嘛……早期的作品经常被人吐槽表情呆板,嘴巴动起来像在嚼橡皮泥,而且各帧画面之间连贯性也不咋地,容易抽抽-5。
后来人们琢磨明白了,得有个专门的“监工”来盯着画面质量。这就有了Wav2Lip这类模型,它引入了一个叫“对抗生成网络”的机制,简单说就是弄了两个“裁判”:一个专门挑剔口型同步得准不准,另一个则嫌弃画面清不清晰、真不真实。在这俩“裁判”的严格把关下,生成的角色口型同步率大幅提升,终于不那么像提线木偶了-5。
但人们很快就又不满足了——光嘴动还不行啊,说话时眉毛、眼睛、脸颊肌肉都得跟着动,这才有情绪啊!于是,更厉害的FaceFormer登场了。它借用了一种在自然语言处理里大放异彩的Transformer模型来理解声音的上下文。这玩意儿就像给AI装上了“理解力”,让它能联系一句话的前后语境来驱动整个面部的表情。比如说到“惊喜”时,AI不仅会让嘴巴张开,还可能配上睁大的眼睛和上扬的眉毛,表情就生动多了-5。这技术一出来,可把动画师们乐坏了,很多重复性的、繁琐的逐帧调整工作,终于能交给AI打下手了-10。
一键成片:创作的门槛被踏平了
技术底子打牢了,落到咱们普通人手里能玩出什么花样呢?那就得说说像“可灵AI”这样的应用了。它干了一件特别“懒人福音”的事:音画同出-3。啥意思?就是你只需要输入一段描述,比如“一个穿着复古西装的老爷爷,在茶馆里边喝茶边用成都话摆龙门阵,讲到好笑处自己先嘿嘿笑起来”,然后点一下生成。等上一会儿,一段完整的、带有逼真环境音、人物对白、且口型表情完全同步的短视频就做好了-3-6。
这对我们这种普通用户来说,简直是神器。以前想做个简单的动画小故事,你得先学画画、再学剪辑、还得学配音对齐,门槛高得吓人。现在呢?有想法、会描述就行。比如你想做个产品介绍视频,拍好产品照片上传,描述一下“一位专业主播手持产品,用亲切的语气介绍它的三大功能”,一个带货视频的粗剪版可能几分钟就出来了-6。有游戏开发者就感慨,这类工具把美术人员从繁重的机械劳动中解放了出来,能更聚焦于核心的艺术创意-10。
而且,现在的人声动画AI胃口也越来越杂,不挑食。你让它模仿央视播音腔,它能给你整得字正腔圆;你让它带点东北大碴子味儿,它也能给你掺和进去几分豪爽-4。甚至有些开源模型,像Index-TTS,你只需要给它几秒钟你的声音样本,它就能克隆出你的音色,然后用你的声音去说任何话,还支持你精细地调整哪里停顿、哪个字重读-9。这简直是自媒体创作者的福音,谁还不会有个状态不好、嗓子不舒服的时候呢?
“灵魂”难觅:技术撞上情感的高墙
看到这儿,你可能会觉得,这岂不是万事大吉,真人配音演员和动画师都要下岗了?诶,事情可没这么简单。技术跑得快,有时也会扯着裆。
今年初,某大型流媒体平台就闹了个大笑话。他们偷偷用AI给一部动画片配了音,结果一上线就被观众喷成了筛子。大家吐槽说那声音“冰冷得像导航”、“情绪起伏还没心电图平缓”、“听得人浑身起鸡皮疙瘩”-8。平台顶不住骂,灰溜溜地把片子撤了下来。你看,这就是现阶段人声动画AI最大的软肋:缺乏真正的情感理解和灵魂注入。
AI可以模仿声音的物理波形,可以精准地让嘴角上扬15度,但它很难理解一句台词背后复杂的人物动机、隐秘的内心戏和微妙的文化语境。它不知道“你好坏哦”这句话,用娇嗔的语气和用鄙视的语气说出来,效果是天壤之别。这种深层的、基于人生经验和共情能力的“表达力”,是目前算法难以逾越的鸿沟-8。
所以,现在业界出现了一个挺有意思的“返祖”现象:越是AI配音泛滥,那些真正有演技、有理解力的真人配音演员反而越吃香,身价越高-8。因为大家发现,技术能解决“像不像”的问题,但解决不了“有没有魂”的问题。好的声音表演,是在用嗓音为角色“塑造肉身”,这是艺术创作,而不是数据拟合。
未来已来,但我们仍是舵手
人声动画AI的未来会怎样呢?它会完全取代人类吗?我看未必,更可能的是走向一种“人机协作”的新模式。
一方面,技术本身还在狂飙。比如英伟达开源的Audio2Face模型,就在推动这项技术变得更普及、更易用-10。未来的AI可能会更懂“情绪迁移”,能根据剧本自动判断哪里该悲伤,哪里该激昂-9。甚至结合像Sora这样的视频生成模型,直接从剧本开始,生生“造”出一部电影来-7。有消息说,已经有大厂在尝试用AI主导制作动画电影了,成本和时间都可能大幅缩减-7。
但另一方面,人类的角色可能会从“执行者”向“指挥官”和“鉴赏家”转变。AI会成为超级高效的“万能素材生成器”和“初级动画师”,负责把人类天马行空的创意,快速具象化成海量的视听草稿。而人类创作者则专注于最核心、AI最难替代的工作:提出独一无二的创意、构建深刻的故事内核、定义作品的审美风格,并对AI生成的海量内容进行筛选、评判和艺术升华-3。
这就像当年照相机发明后,绘画并没有死亡,反而催生了印象派、抽象派等更注重主观表达的艺术形式-7。未来,最顶尖的动画作品,可能不再是比拼谁画工更细腻(这部分AI可能做得更好),而是比拼谁的想法更惊人、谁的故事更触动人心、谁的情感表达更真挚。
所以说,别怕。那个会讲四川话的动画老头儿,再活灵活现,它的“魂儿”也是背后的创作者赋予的。技术工具本质上是把双刃剑,一面是效率倍增的诱惑,一面是创造力惰性的陷阱。它能让我们讲的故事被更多人“听见”和“看见”,但故事本身的温度和力量,终究还得来自我们鲜活的人类心灵。这个世界,不会因为多了几个会说话的虚拟形象就变得冰冷,真正决定未来图景温度的,永远是我们如何使用技术的那双手,和那颗充满创意与共情的心。