

咱搞大数据的,谁没用过Hadoop啊?可一提Hadoop,好多人第一反应就是“慢”,查个数据恨不得给你跑半个小时。你心里头是不是也在嘀咕:这玩意儿咋就这么笨呢?其实吧,这事儿不能怪Hadoop,得怪咱们自己没给它指条近道儿。今天咱们就掏心窝子聊聊这个Hadoop索引技术,看看它到底是个啥神仙操作,能让你的查询快得飞起。
我先跟你说句实在话,默认情况下的Hadoop确实是个“憨憨”。它不像MySQL那样,你建个索引它就屁颠屁颠去用。Hadoop那个分布式文件系统(HDFS),它天生就是为存海量数据设计的,那数据一存就是几百个G甚至多少个T。你要是没点“心机”,想查个东西,它就得老老实实把整个数据集翻个底朝天,这种操作叫全表扫描,专业点说就是暴力遍历 -1。你想想,你只想找一根针,结果得把整个草垛子都翻一遍,这不耽误功夫嘛!
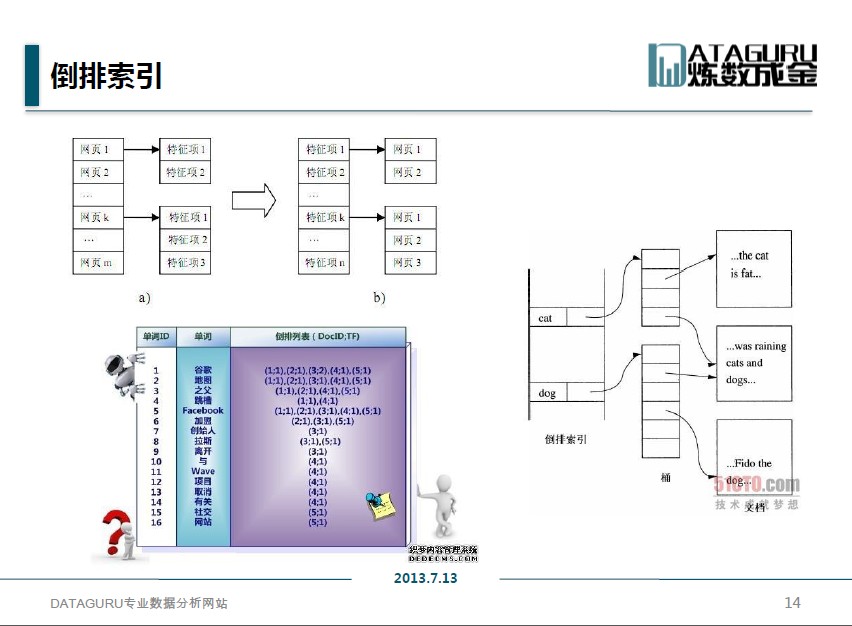
咱们说的这个“近道儿”到底是个啥?这就得请出咱们的主角——Hadoop索引技术。别被这名字唬住,其实道理贼简单。第一次咱们提这个技术,你得明白它解决的最大痛点就是“指哪打哪”。它本质上就是给数据做个“目录”,告诉你你要的那根针大概藏在哪一堆草垛子里,不用你漫无目的地瞎翻。
具体到实际操作里头,常见的玩法有两种:一种叫基于文件的索引,一种叫基于InputSplit的索引 -1。我给你打个比方,你就理解了。假设你有两个大文件,一个500MB,一个250MB。Hadoop处理的时候,会把它们切成一块一块的,每块默认128MB。这么一算,第一个文件被切成了4块,第二个文件被切成了2块(咱们取个整,好理解)。这每一块就是一个InputSplit。
如果你用基于文件的索引,那就比较粗糙了,索引告诉你数据在第一个文件里。得嘞,你就得把第一个文件那4个数据块全扫一遍,这叫“基于文件的索引”。那要是用基于InputSplit的索引呢?那就精细多了,索引能直接定位到具体是哪一块,比如说是第一文件的第2块和第3块。你想想,本来要扫4块,现在只扫2块,这效率是不是翻倍了?这个Hadoop索引技术的精细度,就是你查询快慢的关键。不过我得跟你透个底,在Hadoop里搞这个索引,不像在关系型数据库里点几下鼠标那么舒坦,它得你自己写MapReduce作业去构建和维护,是有那么点麻烦 -1。
接下来咱们聊点高级的,也就是第二次提到Hadoop索引技术。这次咱们得说说它在数据仓库Hive里头是怎么耍的。好多公司都用Hive来分析数据,那家伙,表都是分区的,数据量大了去了。你要是没索引,写个SQL等结果的时候,都能下楼抽根烟再回来。这时候,Hive里的索引就能出来救场了。
Hive里头有两种常用的索引,一种叫紧凑索引,一种叫位图索引 -2。啥时候用紧凑索引呢?比如说你的表有个用户ID列,你经常要根据用户ID查他的消费记录,这种场景就适合用紧凑索引。它存的就是这个ID值和它所在的文件以及偏移量,构建起来快,存得也省地方 -2。那啥时候用位图索引呢?比如说你的表里有个“性别”列,或者“订单状态”列,这一列的值就那么几个选项(男、女,或者待付款、已付款、已退款)。这种重复值特别多的列,就是低基数列。在这种列上建位图索引,那查询组合条件的时候,比如查“男性且已付款的用户”,速度快得惊人 -2。它就是用位图(一串0和1)来标记哪些行有这个值,做逻辑运算那叫一个快。
不过,我得给你泼盆冷水。Hive这索引听着挺美,但维护起来也是个细致活儿。你数据更新了,索引不会自己跟着变,你得记得重建索引,不然索引就成了一张废纸 -2。好多新手在这儿栽跟头,给我整无语了都。索引建了,数据变了,不重建,查询还是慢,然后跑来问我为啥没效果,我能咋说?只能劝你多长个心眼儿。
咱们再深入一层,聊聊HBase这个NoSQL数据库里的索引门道,这也是第三次从更深的层次去理解Hadoop索引技术。HBase自己只有一个基于RowKey的索引,就是你查数据必须得知道那个RowKey长啥样。但实际情况是,咱们经常想根据别的字段,比如说根据商品的颜色或者根据用户的年龄来查,这时候就抓瞎了,就得全表扫描。为了解决这个痛点,社区里的大神们搞出了二级索引 -7。
这二级索引的玩法就更野了。比如说,你可以用Apache Phoenix给HBase加上全局索引或者本地索引 -7。全局索引适合读多写少的场景,就是索引单独放一个表,写入的时候得两边都写,有点慢,但查起来飞快。本地索引呢,适合写多的场景,索引和数据待在同一个Region里,写入的时候不用跨节点,快一些,但查询的时候就没那么极致了 -7。
还有更狠的,如果你要做那种全文检索,比如在几亿条日志里搜包含“报错”和“数据库连接”的句子,那普通的二级索引就搞不定了。这时候就得请出Solr或者Elasticsearch这种引擎,配合HBase-Indexer这种工具,HBase里数据一写入,实时就给同步到Solr里去建倒排索引 -7。查询的时候,先通过Solr找到符合条件的RowKey,然后再去HBase里把整行数据捞出来。这就是强强联合,把Hadoop索引技术的威力发挥到了极致。
所以你看,这Hadoop生态里的索引技术,它不是一个死板的玩意儿,得活学活用。没有一招鲜吃遍天的办法。你得根据你的数据长啥样,你的查询咋写的,还有你是读多还是写多,综合起来考虑。别老抱怨Hadoop慢,先回头看看自己有没有把这些“近道儿”用起来。希望我今儿个掏心窝子的这些话,能帮你把这个坎儿迈过去。






