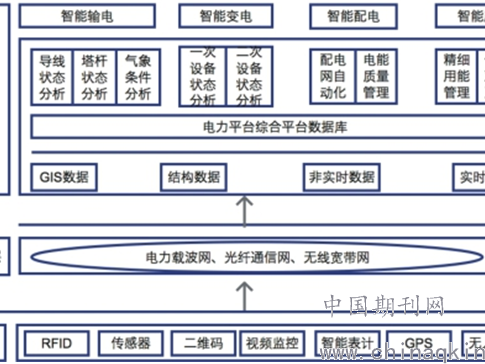
你有沒有這樣的經歷?對著智能音箱字正腔圓地發號施令,它卻給你播放了一首毫不相干的歌曲;或者試圖用語音輸入一段文字,結果發現轉換出來的內容錯漏百出,讓人啼笑皆非。這背後的核心挑戰之一,就是「ai字拼讀」技術——如何讓人工智能準確地將人類複雜多變的語音信號,轉換為一個個正確的文字。這項技術遠不止是簡單的「聽寫」,它需要機器理解不同口音、適應各種噪音環境,甚至揣摩語句中的情感色彩。今天,咱們就來嘮嘮這個讓機器變得「耳聰目明」的關鍵技術,看看它是如何一步步學習,並悄然改變我們與數字世界對話的方式的-2。
從聲音到文字:一場精密的數字解碼之旅

所謂「ai字拼讀」,本質上是讓計算機模擬人類聽覺與語言理解的能力。它不像我們小時候學拼音那樣有明確的規則表,而是需要通過海量的數據「餵養」和複雜的模型「訓練」才能獲得。這個過程,可比我們學說話要複雜多了。
AI需要「聽清」。它通過麥克風捕捉到的是一連串連續的波形數據。第一步是進行特徵提取,將這些波形轉化為更能體現聲音特點的數字特徵,比如梅爾頻率倒譜係數(MFCC)。你可以把它想像成給聲音拍一張高維度的「聲紋照片」,這張照片捕捉的是聲音的頻譜、能量等關鍵信息,而不是原始的聲音波形本身。這一步至關重要,就好比廚師做菜前要先處理好食材,後續的「烹飪」(模型識別)才能順利進行-6。

接著,AI要開始「聽懂」。這就需要動用預先訓練好的聲學模型和語言模型。聲學模型負責解決「這個聲音對應哪個發音單元(音素或字節)」的問題。它就像一個受過嚴格訓練的語言學家,能從千差萬別的個人嗓音中,辨識出共通的發音元素。例如,無論是北京話兒化音還是吳語軟儂的語調,聲學模型都要努力將它們映射到標準的拼音或音素上-2。為了讓這個「語言學家」見多識廣,研究人員需要為它準備極其豐富的訓練數據。這些數據需要覆蓋不同的口音、性別、年齡、語速,甚至各種真實環境下的噪音背景,比如車載環境的風噪、辦公室裏的鍵盤聲、家庭環境中的電視背景音等-6。只有這樣,模型在實際應用中才不會因為環境稍一變化就「失聰」。
光有聲學模型還不夠。同樣的發音,在不同的上下文裏可能對應完全不同的字詞。這時就需要語言模型出馬了。語言模型基於海量的文本數據訓練而成,它掌握了語言的統計規律,能夠判斷哪個詞序列更合理、更常見。比如,聽到「wo3 yao4 shui4 jiao4」這個發音序列,語言模型會基於常識判斷「我要睡覺」的概率遠大於「我要稅交」或「我要水餃」(儘管後者在特定情境下也成立),從而糾正聲學模型可能的誤判,輸出最可能的文本結果-2。這兩個模型協同工作,共同完成了從聲音到文字的驚險一躍。
「南腔北調」的挑戰:為何AI聽不懂你的家鄉話?
儘管技術不斷進步,但讓AI準確識別所有人的語音,尤其是帶有濃重地方口音的語音,仍然是一個巨大的挑戰。這正是當前「ai字拼讀」技術需要重點攻克的難點之一。很多通用語音識別模型是基於標準普通話或英語(如美式英語)訓練的,當遇到粵語的九聲六調、閩南話豐富的連讀變音,或是帶有濃重東北腔、四川話味道的普通話時,模型的表現就可能大打折扣-2。
為了解決這個問題,技術人員想出了不少辦法。一種行之有效的策略是 「遷移學習」與「微調」 。簡單來說,就是先讓模型在一個巨大的、通用的語音數據集上學習,打好基礎(預訓練)。然後,再使用特定方言或口音的、相對較小的數據集對這個已經「學有所成」的模型進行二次訓練(微調),讓它專門適應這種方言的特點。這就好比一個掌握了標準普通話的人,去到某個方言區生活一段時間,通過不斷的耳濡目染,也能漸漸聽懂甚至學會當地的話-2。為了獲取這些寶貴的方言數據,有時需要通過眾包的方式,邀請來自各地的志願者錄音,或者與地方文化機構合作進行採集-2。
另一個關鍵在於對聲學模型和語言模型進行深度定制。對於聲學模型,需要擴充其音素詞典,加入方言裏特有的發音單元,並針對方言獨特的聲調和韻律進行建模-2。對於語言模型,則需要構建包含大量方言詞彙和慣用表達的文本庫。比如,系統需要知道「巴適」在四川話裏意味著「舒服、好」,「靚女」在粵語裏是對女性的稱呼,而「兀突」在某些中原官話裏可能表示「不穩定」。只有這樣,AI在聽到這些詞時,才不會一頭霧水-2。
不止於聽寫:ai字拼讀的廣闊應用天地
當「ai字拼讀」變得越來越精準,它的用武之地就遠遠超出了簡單的語音輸入法。它正在成為眾多智能化應用的基礎設施,深刻融入我們的學習、工作和生活。
在語言學習領域,它扮演著「AI外教」的耳朵和嘴巴。先進的英語學習APP已經能夠實時評估用戶的口語發音,進行音素級別的糾正。例如,系統可以精準識別用戶是否將「think」裏的/θ/音發成了/s/音,並給出可視化的嘴型指導和發音示範-10。這背後離不開高性能的語音識別技術,只有先「聽」得極其準確,才能給出有效的反饋。更有研究通過結合強化學習與大語言模型,構建了個性化的自動語音治療系統,能夠像一位耐心的老師一樣,提供詳細、有針對性且富有鼓勵性的糾音反饋-5。
在客戶服務與會議場景中,實時語音轉寫技術極大提升了效率。開會時,AI可以實時生成文字記錄,並自動提取會議紀要和行動項-8。在客服中心,通話能被即時轉錄並分析,幫助快速定位客戶問題,甚至評估客服人員的服務質量。為了在這類複雜場景(可能包含多人對話、交叉打斷、專業術語)中保持高準確率,系統需要針對業務領域的專有詞彙進行優化,比如添加「熱詞」,給某些關鍵業務名詞更高的識別權重,或者直接訓練定制化的語言模型-7。
在智能硬件和無障礙領域,精準的「ai字拼讀」更是賦予了設備與用戶自然對話的能力。從智能家居的語音控制(「打開客廳的空調」)到車載系統的語音指令(「導航到最近的加油站」),再到為聽障人士提供的實時語音轉文字服務,這項技術正在默默填平數字世界的交互鴻溝,讓更多人能夠便捷地享受科技帶來的便利-6。
展望未來:更自然、更包容、更智能的對話
未來的「ai字拼讀」技術,將朝著更人性化的方向發展。它會變得更具包容性,能夠更好地理解各種少數語言、瀕危方言,以及因生理條件造成的特殊語音(如構音障礙)。這不僅是技術進步,更是數字時代的文化保護與社會關懷-2。
識別將從單純的「聽詞」走向深度的「聽意」。未來的系統會更注重理解語句背後的意圖、情感和上下文。例如,同樣一句「房間有點冷」,在不同的語境和語氣下,可能是在陳述事實、表達不滿,或者隱含著「請關小空調」的請求。結合大語言模型強大的理解能力,AI將有望做到這一點,使人機對話更加順滑、自然,充滿「人情味」-1。
隨著邊緣計算和微型化模型的發展,高精度的實時語音識別將能離線運行在手機、耳機甚至更小的物聯網設備上。這不僅能保護用戶隱私(語音數據無需上傳雲端),還能實現無網絡環境下的穩定服務,讓智能語音交互真正無處不在-3。
從磕磕絆絆到對答如流,讓AI聽懂人類豐富多樣的語言,是一條漫長而有趣的道路。每一次我們對著設備清晰地說出指令並得到準確回應,背後都是數據、算法和工程師們無數次優化的結果。或許不久的將來,帶著任何口音的你,都能和任何智能設備輕鬆、自然地「嘮家常」,那將是一個真正充滿「耳聰目明」的智能體的世界。